丂丂
丂丂
丂愭傎偳怣崋傪Gaussian Filter偱廳傒晅偗傪峴偭偨偑丄暘愅壔妛偱傛偔巊傢傟偰偄傞
Saviztky Golay朄偵娭偟偰媍榑偡傞丅侾俋俇係擭椉幰偑敪昞偟偨僨乕僞偺僗儉乕僕儞僌庤朄偱偁傞丅
偙偺庤朄偼丄椬愙偡傞俀N亄侾偺僨乕僞偵懳偟偰丄倣師偺懡崁幃偱嬤帡偟偰俀N亄侾偺拞墰抣偺尦僨乕僞傪
偦偺倶偺埵抲偺嬤帡懡崁幃偺倷乮倶乯偵抲偒姺偊偰偄偔偙偲偱丄僲僀僘傪掅尭偝偣偰偄偒傑偡丅
偙偺庤朄偼幚幙揑偵廳傒晅偒堏摦暯嬒偱偁傞丅
摿挜
- 懡崁幃嬤帡偵傕偐偐傢傜偢丄嬤帡偵巊偆僨乕僞偺揰悢偲嬤帡偡傞懡崁幃偺師悢偩偗偱學悢偑寛傑傞
- 僗儉乕僕儞僌偩偗偱側偔丄暯妸壔旝暘傕寁嶼偱偒傞
乮3師埲忋偺懡崁幃偱嬤帡偡傞応崌偼2師旝暘埲忋傕壜擻乯 - 僗儉乕僕儞僌偺庤朄偵傕偐偐傢傜偢丄僺乕僋偑撦傝偵偔偄
- 幚幙偼廳傒晅偒堏摦暯嬒側偺偱丄張棟偑崅懍
偙偺傛偆偵偙偺僼傿儖僞偼忋婰偺摿挜傪帩偮偨傔偵暘愅壢妛偱傛偔梡偄傜傟偰偄傞丅
Saviztky Golay偺摫弌
丂傑偢丄嵟弶偵摍娫妘偱暲傫偩僨乕僞偵偮偄偰丄俀N亄侾揰傪倣師懡崁幃
偱嬤帡偡傞偙偲傪峫偊傑偡丅
偙偺帪僨乕僞偺倶偺抣偼亅俶儮倶丂乣丂俶儮倶偲彂偔偙偲偑偱偒傑偡丅
偡傞偲倶偲倷偺僨乕僞偺慻偼丄乮亅N儮倶丄倷乮亅俶儮倶乯乯丄乮亅(N-1)儮倶丄倷乮亅(俶-1)儮倶乯乯丄丄丄丄
乮N儮倶丄倷乮俶儮倶乯乯偲側傞丅偙傟傜偺僂傿儞僪僂撪偵偁傞僨乕僞揰傪倣師偺懡崁幃偱嬤帡僼傿僢僩偡傞
偲峫偊傟偽傛偔偦偺帪偺嵟彫擇忔朄偼丄
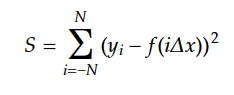
偱偁傝丄偙傟傪曃旝暘偟偰0偲抲偄偨帪偺夝偼丄
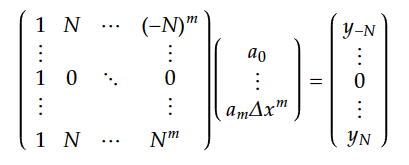
傪夝偔偙偲側傞丅嵍偺峴楍幃傪X偲抲偔偲丄嬤帡懡崁幃偺學悢乮a0丄丄丄丄am儮倶倣乯偼丄
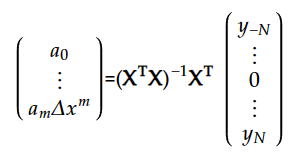
偱梌偊傜傟傑偡丅
Savi倲zky Golay朄偼幚嵺偺張棟偱嬤帡懡崁幃偵抲偒姺偊傜傟傞偺偼俀N亄侾偺拞墰偺揰偺傒偱
懠偺抣偼巊傢側偄丅偦偺帪偺抣偼倖乮倶乯亖倖乮侽乯偺帪偺抣偱偁傞丅偮傑傝丄偙傟偼倖乮侽乯亖a侽偲摨偠偵側傞丅
偙偺a0偼尦僨乕僞倷乮俶儮倶乯偵埶懚偟偰偄側偄偺偱丄峴楍偺1峴栚偲倷僨乕僞楍偺撪愊傪寁嶼偡傞偩偗偱
媮傔傞偙偲偑偱偒傞丅偟偐傕倷偲偺峴楍愊傪偲傞峴楍偼僨乕僞悢俶偲倣師偵埶懚偡傞偩偗偱丄
僨乕僞倷偵埶懚偟側偄偺偱枅夞峴楍梫慺偼摨偠偱偁傞偺偱丄堦夞帠慜偵寁嶼偟偰偍偗偽
巊偄傑傢偡偙偲偑偱偒傞丅偮傑傝奺揰倷偺嬤帡傪媮傔傞嵺偵枅夞寁嶼偡傞昁梫偑側偄丅
傑偨旝暘僨乕僞傕倖乫乮侽乯亖a1儮倶丄倖乭乮侽乯亖俀 x a2儮倶丱俀偱偁傞偺偱旝暘僨乕僞傕娙扨偵媮傔傞偙偲偑偱偒傑偡丅
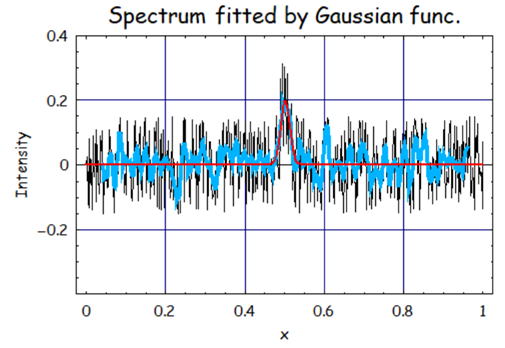
偱偼幚嵺偵SavitzkyGolay朄傪梡偄偰暯妸壔偡傞條巕傪尒偰傒傛偆丅
慜夞偲摨條偵尦怣崋偼丄A亖侽丏俀丄倣亖侽丏俆丄冃亖侽丏侽侾偺僈僂僗怣崋偵丄
僲僀僘怣崋亇侽丏侾俆傪帩偮儔儞僟儉僲僀僘傪壛偊偨怣崋偱偁傞丅
侾丏僼傿僢僥傿儞僌懡崁幃師悢丗倣亖俆丄倂indow僒僀僘乮僼傿僢僥傿儞僌僨乕僞揰悢乯亖俋丄旝暘師悢亖侽偺帪
SavitzkyGolay學悢丄乷0.034965, -0.128205, 0.0699301, 0.314685, 0.417249,
0.314685, 0.0699301, -0.128205, 0.034965乸偼僼傿僢僥傿儞僌偝傟傞僨乕僞揰悢偲摨偠梫慺悢傪傕偮丅
偙偺學悢偲僂傿儞僪僂僒僀僘撪偵偁傞奺俋僨乕僞偲偺撪愊傪偲傞偙偲偱丄1斣栚偺僨乕僞傪惗惉偡傞丅
忋偱傕弎傋偨偑偙偺學悢偼丄倣丄倂倝値倓倧倵僒僀僘丄旝暘師悢偑寛傑傟偽堦堄偵寛傑傞丅
幚嵺偵俽倎倴倝倲倸倠倷俧倧倢倎倷朄偱暯妸壔偟偨寢壥傪帵偡丅
僼傿僢僥傿儞僌寢壥偼A亖侽丏俀俀丄倣亖侽丏俆侽侽丄冃亖侽丏侽侾侾偱偁傞丅庒姳偺僲僀僘惉暘偼彫偝偔側偭偰偄傞偑丄
傑偩尦僨乕僞偵嬤偟偄怣崋偱偁傞傕偺偺僼傿僢僥傿儞僌寢壥尦偺僈僂僗娭悢偵嬤偔傛偔僼傿僢僥傿儞僌偱偒偰偄傞丅
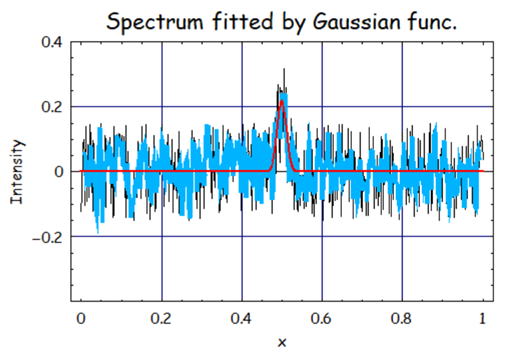
俀丏僼傿僢僥傿儞僌懡崁幃師悢丗倣亖俆丄Window僒僀僘乮僼傿僢僥傿儞僌僨乕僞揰悢乯亖係侽丄旝暘師悢亖侽偺帪
偱偼師偵倂倝値倓倧倵僒僀僘偩偗傪戝偒偔偟偰傒傛偆丅僼傿僢僥傿儞僌僨乕僞揰悢傪憹傗偟偰偄傞偺偱
僨乕僞偼傛傝暯妸壔偝傟傞偙偲偑梊憐偝傟傞丅
尒偰傢偐傞傛偆偵崅廃攇惉暘偼傎偲傫偳偒傟偄偵彍奜偱偒偰偄傞偙偲偑傢偐傞丅
堦曽偱Window僒僀僘傛傝戝偒偄廃攇悢惉暘儮倶丗0.002倶倂倝値倓倧倵僒僀僘丗40亖0.08埲忋偺僲僀僘偼
巆偭偰偄傞丅堦曽偱崱夞偺僈僂僗怣崋偼忋婰侽丏侽俉傛傝偼嵶偄怣崋偱偁傞偺偵傕偐偐傢傜偢丄
怣崋偼偼偭偒傝偲尒偰庢傟傞丅
偙偺暯妸壔偟偨怣崋偺僼傿僢僥傿儞僌寢壥偼丄A亖侽丏侾係丄倣亖侽丏係俋俇丄冃亖0.012偱偁傞丅
怣崋偺嫮搙偼庛偔側偭偰偄傞傕偺偺怣崋偼偟偭偐傝偲傢偐傞丅
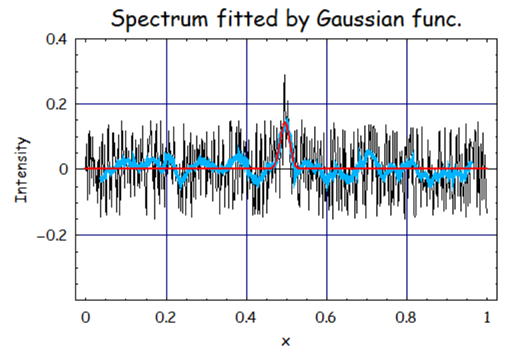
俁丏僼傿僢僥傿儞僌懡崁幃師悢丗倣亖侾侽丄Window僒僀僘乮僼傿僢僥傿儞僌僨乕僞揰悢乯亖係侽丄旝暘師悢亖侽偺帪
偱偼師偵僼傿僢僥傿儞僌師悢傪憹傗偟偰尒傛偆丄僼傿僢僥傿儞僌師悢偑憹偊傞偲傛傝崅廃攇傑偱嬤帡偱偒傞偺偱丄
僲僀僘偼徚偟偯傜偄偑丄怣崋嫮搙偼堐帩偝傟傞偲偄偆偙偲偑梊憐偝傟傞丅
暯妸壔偟偨怣崋偺僼傿僢僥傿儞僌寢壥偼丄A亖侽丏侾俋俇丄倣亖侽丏俆侽侾丄冃亖0.012偱偁傞丅
僨乕僞怣崋偼暅妶偟偰侽丏俀偵嬤偯偄偰偄傞偑丄僲僀僘偺検偼憹壛偟偰偄傞丅
寢嬊寁嶼晧壸傕峫偊傞偲僂傿儞僪僂僒僀僘傪曄偊偰偁傞掱搙傎偟偄SN斾傑偱棃偨傜丄
偦偙傑偱師悢傪偁偘偰傕寢嬊S偼憹偊傞偑SN偼埆壔偡傞偺偱丄倣傪愊嬌揑偵偁偘傞棟桼偼撪梕偵巚傢傟傞丅
杮奿揑偵暋嶨側怣崋偺宍傪偟偰偄偨応崌偼師悢傪偁偘傞昁梫偑偁傞偺偐傕偟傟側偄偑丄
崱夞偼偦偙傑偱媍榑偱偒偰偄側偄丅