 丂丂
丂丂
丂愭傎偳Savitzky Golay朄傪梡偄偰Smoothing傗偦偺旝暘傪峴偭偰僺乕僋専弌傪峴偭偨丅
師偵Savitzky Golay朄傎偳桳柤偱偼側偄偑1922擭偵Whittaker偵傛偭偰敪昞偝傟偨Smoothing朄偱偁傞丅
偙偺屻丄2003擭偵Eilers偑2003擭偺榑暥偵Whittaker偺曽幃傪墳梡偟偨AsLS朄偲偄偆儀乕僗儔僀儞悇掕朄傪
敪昞偡傞偲暘岝僗儁僋僩儖傗僋儘儅僩僌儔儉偺儀乕僗儔僀儞悇掕庤朄偲偟偰Whittaker偵拲栚偑廤傑傝丄
悢乆偺墳梡庤朄偑嶌傜傟偨丅Whittaker偺Smoothing朄偺摿挜偲偟偰
摿挜
- 斾妑揑抁偄僐乕僪偱幚尰偱偒傞
- 慳峴楍偺寁嶼偵懳墳偟偰偄傟偽丄懡悢偺娤應抣偵懳偟偰傕斾妑揑抁帪娫偱僗儉乕僕儞僌偱偒傞
- 寚棊僨乕僞偵懳墳偱偒傞
- 妸傜偐偝傪惂屼偱偒傞
Whittaker偺摫弌
丂傑偢丄娤應偝傟偨應掕僨乕僞偺楍傪丂倷亖乮倷侾丄倷俀丄丒丒丒丒丄倷倣乯偲偡傞丅
偙偺抣偵捠忢僲僀僘側偳偑忔偭偰偄傞偙偲偐傜僨乕僞傪僌儔僼偵昤偔偲側傔傜偐側慄偵側傝傑偣傫丅
師偵妸傜偐側僨乕僞楍丂倸亖乮倸侾丄倸俀丄丒丒丒丒丄倸倣乯傪峫偊丄倸傪倷偵揔崌偝偣傞偙偲傪峫偊傞丅
偦偺偨傔偵偼丄2偮偺偙偲傪峫椂偵擖傟傞昁梫偑偁傝傑偡丅
- 倷偵懳偡傞倸傊偺揔崌嬶崌丂仺丂嵎偺擇忔榓丂乮倷値亅倸値乯丱俀
- 倸偺慹偝丂仺丂倸偺倱夞嵎暘偺擇忔榓丂乮儮倱丂倸値乯丱俀
偱偁儕丄偦傟偧傟傪悢幃偱昞尰偡傞偙偲偑偱偒傞丅
倸偑側傔傜偑偱偁傞傎偳丄僲僀僘偑偁傞僨乕僞楍倷偐傜槰棧偡傞偨傔丄椉幰偼憡斀偡傞梫慺偲側傞丅
埲忋偐傜丄椉幰傪峫椂偟偨撪梕傪悢幃偵棊偲偟崬傓偲儁僫儖僥傿晅偒嵟彫擇忔朄偺栤戣偲側傞丅
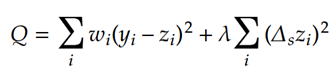
偙偙偱wi偼廳傒傪昞偟丄侽亝倵i亝侾偱偡丅寚棊僨乕僞傗奜傟抣側偳偵懳偟偰丄侽傑偨偼侽偵嬤偄抣傪
梌偊傑偡丅傑偨丄兩偼儁僫儖僥傿學悢偱偡丅兩傪戝偒偔偡傟偽慹偝偺崁偑桪惃偲側傝丄傛傝妸傜偐側
嬋慄惗惉偡傞偙偲偑偱偒傑偡丅
忋婰偺悢幃傪峴楍偲儀僋僩儖偱昞偡偲丄
偲側傝傑偡丅
偙偙偱丄W偼廳傒倵亖乮倵侾丄倵俀丄丒丒丒丄倵倣乯傪懳妏偵攝抲偟偨懳妏峴楍丄俢倱偼丄
偲側傞傛偆側峴楍偱偡丅椺偊偽丄倣亖俁丄倱亖侾偱偼丄
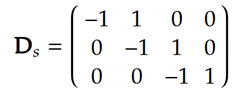
倣亖俆丄倱亖俁偱偁傟偽丄
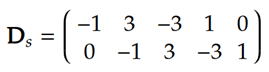
偲側傞丅
師偵忋偵偁傞峴楍幃傪倸偱曃旝暘偟偰丄
偦傟傪侽偲妸傜偐側娭悢倸偱昡壙娭悢俻偺曄壔偑嵟彫偲側傞応崌傪寁嶼偡傞偲
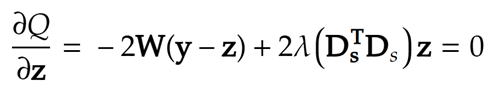
偲側傝丄
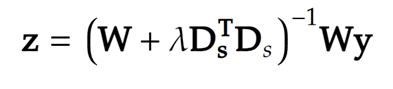
偱偁傞丅偙傟傪寁嶼偡傞偙偲偱丄妸傜偐側僨乕僞楍倸傪媮傔傞偙偲偑偱偒傑偡丅
Eiler倱偵傛傞偲倱亖俀偵偡傞偙偲偱偆傑偔婡擻偡傞偙偲偑懡偄偲偺偙偲偱偡丅
偱偼幚嵺偵Whittaker丂Smoothing傪梡偄偰暯妸壔偡傞條巕傪尒偰傒傛偆丅
慜夞偲摨條偵尦怣崋偼丄A亖侽丏俀丄倣亖侽丏俆丄冃亖侽丏侽侾偺僈僂僗怣崋偵丄
僲僀僘怣崋亇侽丏侾俆傪帩偮儔儞僟儉僲僀僘傪壛偊偨尦怣崋傪峫偊傞丅
侾丏S亖2丄兩亖侾丄倂倝亖1偺応崌
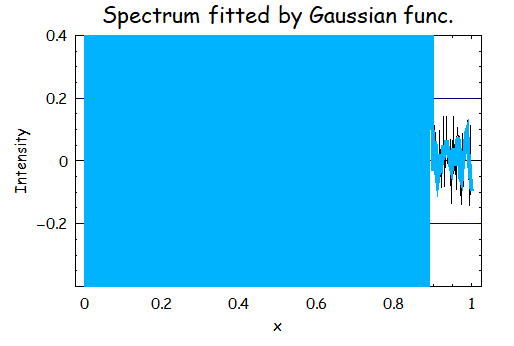
偙偺寢壥傪尒偰傒傞偲丄姰慡偵0.9傛傝彫偝偄偲偙傠偱敪嶶偟偰偄傞丅
偙偙偱兩傪戝偒偔偡傞偐丄廳傒倂倝傪彫偝偔偡傞偐偟側偄偲偙偺敪嶶偼巭傔傜傟側偄丅
俀丏S亖2丄兩亖侾侽丱俆丄倂倝亖侾偺応崌
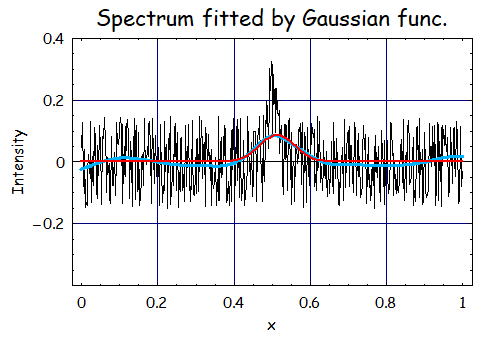
師偵兩傪戝偒偔偟偨嵺偵偳偺傛偆側寢壥偵側傞偺偐傪専摙偟偨丅
敪嶶偼梷偊傜傟偰偄傞偟丄僲僀僘偼旕忢偵傛偔暯妸壔偝傟偰偄傞丅偦偺堊偐丄怣崋偑僽儘乕僪偵側偭偰偍傝
偙偺帪偺僼傿僢僥傿儞僌寢壥偼A亖侽丏侽俉俇丄倣亖侽丏俆侾俁丄冃亖侽丏侽係俈偱偁傞丅
偙偺寢壥傪尒偰傕丄怳暆偑偮傇傟偰偄傞偺偑傢偐傞丅
俁丏S亖2丄兩亖侾丄倂倝亖0.5偺応崌
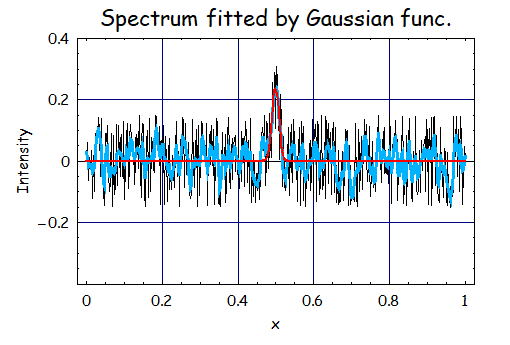
廳傒Wi傪0.5偵曄偊偰傒偨嵺偵偳偺傛偆側寢壥偵側傞偺偐傪専摙偟偨丅
廳傒Wi傪彫偝偔偡傞偙偲偱廂懇偟偰偄傞偺偑暘偐傞丅怣崋傕堐帩揑偱偄傞偑丄僲僀僘偺崅廃攇惉暘偑庢傝愗傟偰偄側偄堊丄
愭傎偳偺兩傪曄峏偡傞応崌偲斾妑偟偰暯妸壔丄摿偵崅廃攇惉暘偺暯妸壔丄偼偁傑傝偱偒偰偄側偄丅
偙偺帪偺僼傿僢僥傿儞僌寢壥偼A亖侽丏俀係丄倣亖侽丏係俋俋丄冃亖侽丏侽侽俋俀偱偁傞丅
僼傿僢僥傿儞僌偼傛偔偱偒偰偄傞偑丄幚嵺偼暋悢夞僼傿僢僥傿儞僌張棟傪峴偆偲丄
僲僀僘傪僼傿僢僥傿儞僌偟偰偟傑偆偙偲傕婲偙偭偰偟傑偆丅偦偺堊傕偆彮偟崅廃攇傪梷惂偟偨偄丅
係丏S亖2丄兩亖侾0丄倂倝亖0.5偺応崌
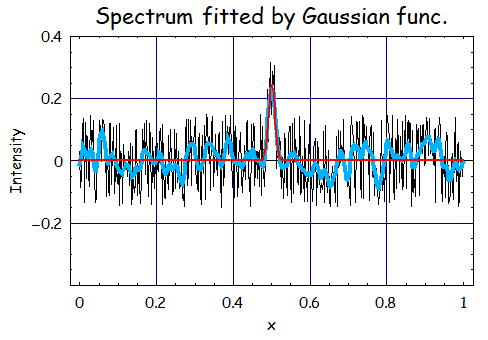
愭傎偳偺専摙偐傜
廳傒兩傪曄峏偡傞偲丄掅丒崅廃攇椉曽偲傕僲僀僘傪掅尭偡傞偙偲偑壜擻偱偁傞偑丄恀偺怣崋傕僽儘乕僪偵偡傞
堦曽丄
倂倝傪曄峏偡傞偲丄掅廃攇偺僲僀僘偼掅尭偱偒丄怣崋傕僽儘乕僪偵側傜側偄偑丄崅廃攇偺僲僀僘偼巆偭偰偟傑偆丅
偙偙傜曈偺僶儔儞僗傪惍偊傞偙偲偑昁梫偵側傞偺偱丄
廳傒Wi傪0.5偵曄偊偰丄兩傪10偵偟偨寢壥傪忋偵帵偡丅崱夞傕廂懇偟偰丄暯妸壔傕側偝傟偰偄傞丅
僲僀僘偺崅廃攇惉暘偼娚傗偐偵側偭偰偄傞堦曽偱丄僺乕僋嫮搙傕偦偙傑偱庛偔側偭偰偄側偄丅
偙偺帪偺僼傿僢僥傿儞僌寢壥偼A亖侽丏俀係俁丄倣亖侽丏俆侽侽丄冃亖侽丏侽侽俉俈偱偁傞丅