
目次
RealSenseセンサの立ち上げ
Intel RealSenseは、デブスカメラの1つです。カラーカメラの映像とデプスカメラの映像を取得でき、これにより、3Dスキャンや物体検出などのタスクを実行できます。今後機械学習での物体認識等をこのRealSenseを用いて行っていきたいと考えているので、まずはRealSenseをPythonで制御できることを試してみた。
事前準備すること
- Intel RealSenseカメラ:D435
- RealSense SDK 2.0:公式サイトからダウンロード
- Python:インストール
- pyrealsense2:Python用RealSenseライブラリのインストール
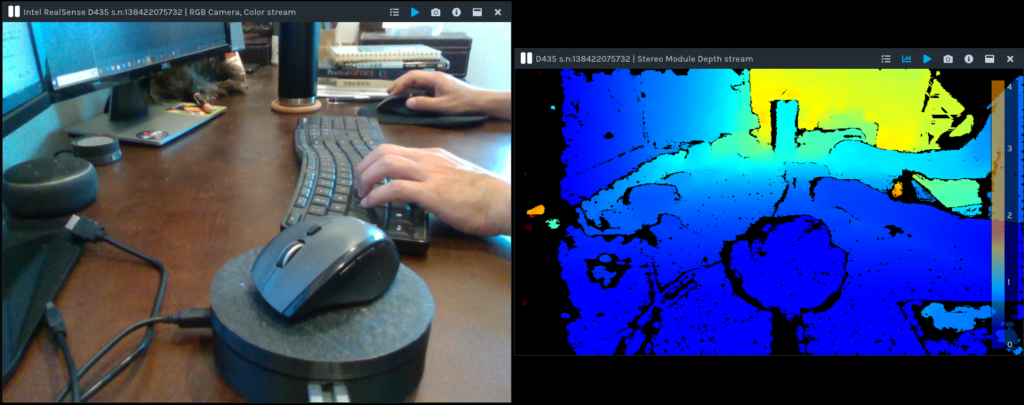
*Pythonでの動作の確認の前にRealSenseの動作を事前に確認する場合は、専用のViewerがあるのでそれをインストールして実際の動作を確認することも可能である。私の場合は、Intel RealSense Viewerを用いた。その結果を下に示す。上の画像が2Dモード、下の画像が3Dモードである。

Pythonへの実装
全ソースコードはRealSenseとYOLO7を用いた物体検出のコードである。ここでは、RealSenseの画像取得の部分にフォーカスして述べる。
以下のPythonスクリプトは、Intel RealSense D435カメラを使用してカラー画像と深度画像をストリーミングし、それらを表示するものです。以下はスクリプトの詳細です。これを実行することで先ほどIntel RealSense Viewerで用いたのと同じ結果を出力することが可能である。
Intel RealSense D435カメラのカラー画像と深度画像のストリーミング
pyrealsense2モジュールをインポートしています。これはIntel RealSense SDKのPythonラッパーです。- カメラの設定を行っています。カラー画像と深度画像のストリームを有効にし、解像度とフォーマットを指定しています。
- パイプラインを作成し、カメラを開始しています。
- カラー画像と深度画像をアラインメントしています。アラインメントにより、カメラから取得した画像が正確に対応するようになります。
- カラー画像と深度画像を取得しています。どちらかが取得できない場合は、次のフレームを待機します。
- カラー画像をNumPy配列に変換しています。
- 深度画像をカラーマップに変換しています。深度マップはジェットカラーマップで表示されます。
- カラー画像と深度画像を表示しています。キー入力で終了できるようにしています。
import cv2
import pyrealsense2 as rs
import numpy as np
def detect(save_img=False):
config = rs.config()
config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)
config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)
pipeline = rs.pipeline()
profile = pipeline.start(config)
align_to = rs.stream.color
align = rs.align(align_to)
times = []
times2 = []
while(True):
#t0 = time.time()
frames = pipeline.wait_for_frames()
aligned_frames = align.process(frames)
color_frame = aligned_frames.get_color_frame()
depth_frame = aligned_frames.get_depth_frame()
if not depth_frame or not color_frame:
continue
img = np.asanyarray(color_frame.get_data())
depth_image = np.asanyarray(depth_frame.get_data())
depth_colormap = cv2.applyColorMap(cv2.convertScaleAbs(depth_image, alpha=0.08), cv2.COLORMAP_JET)
# Stream results
cv2.imshow("Recognition result", img)
cv2.imshow("Recognition result depth",depth_colormap)
if cv2.waitKey(1) & 0xFF == ord('q'):
breakソースコード
import argparse
import time
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
from numpy import random
from yolov7.models.experimental import attempt_load
#from utils.datasets import LoadStreams, LoadImages
from yolov7.utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path
from yolov7.utils.plots import plot_one_box
from yolov7.utils.torch_utils import select_device, load_classifier, time_synchronized, TracedModel
import pyrealsense2 as rs
import numpy as np
def detect(save_img=False):
source, weights, view_img, save_txt, imgsz, trace = opt.source, opt.weights, opt.view_img, opt.save_txt, opt.img_size, not opt.no_trace
# Directories
save_dir = Path(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok)) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(opt.device)
print("device: ", device.type)
half = device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check img_size
if trace:
model = TracedModel(model, device, opt.img_size)
if half:
model.half() # to FP16
# Second-stage classifier
classify = False
if classify:
modelc = load_classifier(name='resnet101', n=2) # initialize
modelc.load_state_dict(torch.load('weights/resnet101.pt', map_location=device)['model']).to(device).eval()
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in names]
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
old_img_w = old_img_h = imgsz
old_img_b = 1
config = rs.config()
config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)
config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)
pipeline = rs.pipeline()
profile = pipeline.start(config)
align_to = rs.stream.color
align = rs.align(align_to)
times = []
times2 = []
while(True):
#t0 = time.time()
frames = pipeline.wait_for_frames()
aligned_frames = align.process(frames)
color_frame = aligned_frames.get_color_frame()
depth_frame = aligned_frames.get_depth_frame()
if not depth_frame or not color_frame:
continue
img = np.asanyarray(color_frame.get_data())
depth_image = np.asanyarray(depth_frame.get_data())
depth_colormap = cv2.applyColorMap(cv2.convertScaleAbs(depth_image, alpha=0.08), cv2.COLORMAP_JET)
# Letterbox
im0 = img.copy()
img = img[np.newaxis, :, :, :]
# Stack
img = np.stack(img, 0)
# Convert
img = img[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Warmup
if device.type != 'cpu' and (old_img_b != img.shape[0] or old_img_h != img.shape[2] or old_img_w != img.shape[3]):
old_img_b = img.shape[0]
old_img_h = img.shape[2]
old_img_w = img.shape[3]
for i in range(3):
model(img, augment=opt.augment)[0]
# Inference
t1 = time_synchronized()
with torch.no_grad(): # Calculating gradients would cause a GPU memory leak
pred = model(img, augment=opt.augment)[0]
t2 = time_synchronized()
times.append(t2 - t1)
times = times[-20:]
# Apply NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
t3 = time_synchronized()
times2.append(t3 - t2)
times2 = times2[-20:]
# Process detections
for i, det in enumerate(pred): # detections per image
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
#s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
label = f'{names[c]} {conf:.2f}'
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)], line_thickness=2)
plot_one_box(xyxy, depth_colormap, label=label, color=colors[int(cls)], line_thickness=2)
# Print time (inference + NMS)
#print(f'{s}Done. ({(1E3 * (t2 - t1)):.1f}ms) Inference, ({(1E3 * (t3 - t2)):.1f}ms) NMS')
im0 = cv2.putText(im0, "Time: {:.2f}ms".format(sum(times) / len(times) * 1000)+" Inference: {:.2f}ms".format(sum(times2) / len(times2) * 1000), (0, 30),
cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 0, 255), 2)
# Stream results
cv2.imshow("Recognition result", im0)
cv2.imshow("Recognition result depth",depth_colormap)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov7.pt', help='model.pt path(s) yolov7-tiny.pt')
parser.add_argument('--source', type=str, default='inference/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.35, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--no-trace', action='store_true', help='don`t trace model')
opt = parser.parse_args()
print("opt:", opt)
#check_requirements(exclude=('pycocotools', 'thop'))
with torch.no_grad():
if opt.update: # update all models (to fix SourceChangeWarning)
for opt.weights in ['yolov7.pt']:
detect()
strip_optimizer(opt.weights)
else:
detect()

コメント
コメント一覧 (1件)
[…] RealSenseセンサー(立ち上げ編) […]