
GANとは
GANとは「Generative Adversarial Networks」の頭文字を取った言葉で、「敵対的生成ネットワーク」ともいわれています。具体的には、GANは2つのニューラルネットワークを競争させることで、新しいデータを生成する機械学習モデルです。一方のネットワークが新しいデータを生成し、もう一方のネットワークがそのデータが本物か偽物かを識別します。この競争を通じて、GANは実在するデータに似た新しいデータを生成することができます。
GANの活用例としては、以下のようなものがあります:
- 画像生成: GANは自動の画像生成が特に有名です。新たに特徴を持ったデータが作り出せるので、データ不足に陥りがちなディープラーニングにも応用することができます。
- 文章から画像生成: 画像をテキストなどの情報から生成することも可能です。
- 画像の特定領域を変換: 画像の中にある特定のスペースを別のものに自然に変換する手法もあります。
- 動画をルールに基づいて変更: GANは動画から動画へと翻訳する技術も高くなっています。
以上のように、GANは多岐にわたる分野で活用されており、その可能性は無限大です。ただし、GANの使用には専門的な知識が必要であり、適切なトレーニングとパラメータ調整が必要となります。また、生成されたデータが現実のデータと区別がつかないほど高品質になると、それが悪用される可能性もありますので、その点には注意が必要です
アーキテクチャ
GAN(Generative Adversarial Networks、敵対的生成ネットワーク)のアーキテクチャは、大きく分けて以下の2つの部分から成り立っています。
- 生成ネットワーク(Generator): このネットワークはランダムなノイズから新しいデータを生成する役割を担っています。 生成ネットワークの目的は、識別ネットワークを欺くことです。つまり、生成ネットワークは、識別ネットワークが本物のデータと区別できないような、リアルなデータを生成しようとします。
- 識別ネットワーク(Discriminator): 識別ネットワークは、生成されたデータと実際のデータを見分ける役割を果たします。識別ネットワークは、生成ネットワークが生成したデータが本物か偽物かを判断します
これら2つのネットワークは、互いに競争しながら学習を進めます。 生成ネットワークは識別ネットワークからのフィードバックを受け取り、このフィードバックを基に、生成ネットワークはパラメータを調整し、より本物に近いデータを生成できるように自身を改善していきます。
GANの学習は以下のようなステップで進行します。
- Discriminatorの学習: まず、Generatorから偽物のデータを生成し、そのデータを使用してDiscriminatorを学習させます。
- Generatorの学習: 次に、GAN全体を使用してGeneratorを学習させます。 このとき、Discriminatorのパラメータは更新されません。
GANの学習を制御するための主要な数式は以下の通りです。
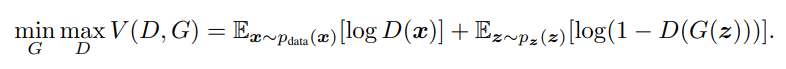
この式の値をGに対しては最小化、Dに対しては最大化したい。
右辺の第一項が本物画像に対する項、第二項が偽物画像に対する項である。D(x)は本物画像xがDに与えられたとき、Dが判別した結果から得られる確率を表す。D(x)が1に近いほど本物画像を本物と判断する。D(G(z))はノイズzから生成された偽物画像G(z)がDに与えられた時、Dが判別した結果から得られる確率を表す。D(G(z))が0に近いほど、偽物画像を偽物と判断する。よって、判別確率Dにとって望ましい状態とは、本物画像は本物、偽物画像は偽物と正しく見分けることで、偽物画像生成Gが望ましい状態とは、Dが本物と間違えるくらいの偽物画像を作成することである。
実行結果
では実際に計算した結果を示してみよう。Epoch=50の時の結果を下に示す。いくつかのセルは最後のほうではきちんと数字になっているかどうか判別できないレベルである。

Epoch = 100まで増やした場合の結果です。もう少し増やした方がはっきりする気がするが上の結果と比較すると手書きの数字が読み取れるレベルになっていると思う。

ソースコード
#https://colab.research.google.com/github/tensorflow/docs-l10n/blob/master/site/ja/tutorials/generative/dcgan.ipynb?hl=ja#scrollTo=Ly3UN0SLLY2l
#を参考にしてプログラムを作成した。
#深層畳み込み敵対的生成ネットワーク(DCGAN)
import tensorflow as tf
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
generator = make_generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
# グラフの表示
#plt.show()
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
# This method returns a helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
EPOCHS = 100
noise_dim = 100
num_examples_to_generate = 16
# You will reuse this seed overtime (so it's easier)
# to visualize progress in the animated GIF)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as you go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
#plt.show()
train(train_dataset, EPOCHS)
ソースコード2 (参考:エラーが消せない)
from keras.models import Sequential
from keras.layers import Dense
from keras.layers.normalization import BatchNormalization
from keras.layers.core import Activation
from keras.layers import Reshape
from keras.layers.convolutional import UpSampling2D
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.layers.core import Flatten
from keras.datasets import mnist
import math
import numpy as np
from keras.optimizers import SGD
from PIL import Image
import argparse
def generator_model():
model = Sequential()
model.add(Dense(1024, input_shape=(100, ), activation='tanh'))
model.add(Dense(128 * 7 * 7))
model.add(BatchNormalization())
model.add(Activation('tanh'))
model.add(Reshape((7, 7, 128), input_shape=(7 * 7 * 128, )))
model.add(UpSampling2D(size=(2,2)))
model.add(Conv2D(64, (5,5), padding='same', activation='tanh', data_format='channels_last' ))
model.add(UpSampling2D(size=(2, 2)))
model.add(Conv2D(1, (5, 5), padding='same', activation='tanh', data_format='channels_last'))
return model
def discriminator_model():
model = Sequential()
model.add(Conv2D(64, (5, 5), padding='same', input_shape=(28, 28, 1),activation='tanh', data_format='channels_last'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128, (5, 5), activation='tanh', data_format='channels_last'))
model.add(Flatten())
model.add(Dense(1024, activation='tanh'))
model.add(Dense(1, activation='sigmoid'))
return model
def generator_contaning_discriminator(generator, discriminator):
model = Sequential()
model.add(generator)
discriminator.trainable = False
model.add(discriminator)
return model
def combine_images(generated_images):
generated_images = generated_images.reshape(generated_images.shape[0],
generated_images.shape[3],
generated_images.shape[1],
generated_images.shape[2])
num = generated_images.shape[0]
width = int(math.sqrt(num))
height = int(math.ceil(float(num) / width))
shape = generated_images.shape[2:]
image = np.zeros((height*shape[0], width*shape[1]), dtype=generated_images.dtype)
for index, img in enumerate(generated_images):
i = int(index/width)
j = index % width
image[i*shape[0]: (i+1)*shape[0], j*shape[1]:(j+1)*shape[1]] = img[0, :, :]
"""Need to check"""
return image
def train(BATCH_SIZE):
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = (X_train.astype(np.float32) -127.5)/127.5
X_train = X_train.reshape((X_train.shape[0], 1) + X_train.shape[1:])
discriminator = discriminator_model()
generator = generator_model()
discriminator_on_generator = generator_contaning_discriminator(generator, discriminator)
d_optim = SGD(lr = 0.0005, momentum=0.9, nesterov=True)
g_optim = SGD(lr = 0.0005, momentum=0.9, nesterov=True)
generator.compile(loss="binary_crossentropy", optimizer="SGD")
discriminator_on_generator.compile(loss="binary_crossentropy", optimizer=g_optim)
discriminator.trainable = True
discriminator.compile(loss="binary_crossentropy", optimizer=d_optim)
noise = np.zeros((BATCH_SIZE, 100))
for epoch in range(100):
print("Epoch is", epoch)
print("Number of batches", int(X_train.shape[0] / BATCH_SIZE))
for index in range(int(X_train.shape[0] / BATCH_SIZE)):
for i in range(BATCH_SIZE):
noise[i, :] = np.random.uniform(-1, 1, 100)
image_batch = X_train[index * BATCH_SIZE:(index + 1) * BATCH_SIZE]
image_batch = image_batch.reshape(image_batch.shape[0],
image_batch.shape[2],
image_batch.shape[3],
image_batch.shape[1])
generated_images = generator.predict(noise, verbose=0)
if index % 20 == 0:
image = combine_images(generated_images)
image = image * 127.5 + 127.5
Image.fromarray(image.astype(np.uint8)).save(
str(epoch) + "_" + str(index) + ".png")
X = np.concatenate((image_batch, generated_images))
y = [1] * BATCH_SIZE + [0] * BATCH_SIZE
d_loss = discriminator.train_on_batch(X, y)
print("batch %d d_loss : %f" % (index, d_loss))
for i in range(BATCH_SIZE):
noise[i, :] = np.random.uniform(-1, 1, 100)
discriminator.trainable = False
g_loss = discriminator_on_generator.train_on_batch(
noise, [1] * BATCH_SIZE)
discriminator.trainable = True
print("batch %d g_loss : %f" % (index, g_loss))
if index % 10 == 9:
generator.save_weights("generator", True)
discriminator.save_weights("discriminator", True)
def generate(BATCH_SIZE, nice=False):
generator = generator_model()
generator.compile(loss="binary_crossentropy", optimizer="SGD")
generator.load_weights("generator")
if nice:
discriminator = discriminator_model()
discriminator.compile(loss="binary_crossentropy", optimizer="SGD")
discriminator.load_weights("discriminator")
noise = np.zeros((BATCH_SIZE*20, 100))
for i in range(BATCH_SIZE*20):
noise[i, :] = np.random.uniform(-1, 1, 100)
generated_images = generator.predict(noise, verbose=1)
d_pret = discriminator.predict(generated_images, verbose=1)
index = np.arange(0, BATCH_SIZE*20)
index.resize((BATCH_SIZE*20, 1))
pre_with_index = list(np.append(d_pret, index, axis=1))
pre_with_index.sort(key=lambda x: x[0], reverse=True)
nice_images = np.zeros((BATCH_SIZE, 1) +
(generated_images.shape[2:]), dtype=np.float32)
for i in range(int(BATCH_SIZE)):
idx = int(pre_with_index[i][1])
nice_images[i, 0, :, :] = generated_images[idx, 0, :, :]
image = combine_images(nice_images)
else:
noise = np.zeros((BATCH_SIZE, 100))
for i in range(BATCH_SIZE):
noise[i, :] = np.random.uniform(-1, 1, 100)
generated_images = generator.predict(noise, verbose=1)
image = combine_images(generated_images)
image = image*127.5+127.5
Image.fromarray(image.astype(np.uint8)).save(
"generated_image.png")
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--mode", type=str)
parser.add_argument("--batch_size", type=int, default=128)
parser.add_argument("--nice", dest="nice", action="store_true")
parser.set_defaults(nice=False)
args = parser.parse_args()
return args
if __name__ == "__main__":
args = get_args()
args.mode = "train"
if args.mode == "train":
train(BATCH_SIZE=args.batch_size)
print("execute1")
elif args.mode == "generate":
generate(BATCH_SIZE=args.batch_size, nice=args.nice)
print("execute2")
コメント